
Akustischer Seitenkanalangriff auf Tastaturen
Akustische Seitenkanalangriffe können Passwörter durch Analyse von Tastaturgeräuschen über Mikrofone abfangen. Angreifer nutzen Deep Learning, um Tastenanschläge zu erkennen
Dieser Artikel dient ausschließlich der Darstellung des aktuellen Forschungsstands zu akustischen Seitenkanalangriffen. Die beschriebenen Techniken und Methoden werden hier nur zu Informations- und Bildungszwecken präsentiert. Die praktische Anwendung dieser Techniken ohne ausdrückliche Erlaubnis ist illegal und kann strafrechtliche Konsequenzen nach sich ziehen. Der Autor und die Plattform distanzieren sich ausdrücklich von jeglicher missbräuchlichen Verwendung dieser Informationen. Leser werden dringend aufgefordert, diese Kenntnisse nur im Rahmen legaler und ethischer Grenzen zu nutzen.
In einer Welt, in der Mikrofone immer allgegenwärtiger werden – durch Smartphones, Laptops und andere Smarte Geräte – entstehen neue Gefahren für die Datensicherheit. Eine dieser Bedrohungen ist der akustische Seitenkanalangriff, der es Angreifern ermöglicht, über ein Mikrofon Tastenanschläge auf einer Tastatur zu erkennen und somit Passwörter oder andere vertrauliche Informationen zu stehlen.
In diesem Blogpost erklären wir, was ein akustischer Seitenkanalangriff ist, wie dieser funktioniert und ob er eine ernsthafte Bedrohung darstellt.
Was ist ein akustischer Seitenkanalangriff?
Ein akustischer Seitenkanalangriff (Acoustic Side Channel Attack, ASCA) ist eine Methode, bei der sensible Informationen wie Passwörter oder kryptografische Schlüssel über die Geräusche eines Systems extrahiert werden. Elektronische Geräte erzeugen bei ihrer Nutzung akustische Emissionen, etwa durch Vibrationen von Spannungsreglern, Lüftern oder mechanischen Komponenten wie Tastaturen. Diese Geräusche sind oft unbewusst wahrnehmbar, können jedoch durch empfindliche Mikrofone präzise aufgenommen und analysiert werden.
Technisch basiert der Angriff auf der Korrelation zwischen den erzeugten Geräuschen und den internen Prozessen des Systems. Beispielsweise ändern sich die Schallprofile einer CPU während komplexer Berechnungen. Durch Signalverarbeitung und maschinelles Lernen lassen sich daraus Rückschlüsse auf die Art der Berechnungen ziehen – etwa bei der RSA-Verschlüsselung. Auch Tastatureingaben lassen sich anhand ihrer individuellen akustischen Signaturen gut rekonstruieren.
Wie funktioniert der Angriff?
Der Angriff läuft in mehreren Schritten ab:
1. Datenerfassung
Der erste Schritt besteht darin, die akustischen Signale der Tastenanschläge zu erfassen und aufzunehmen. Dies kann schon mit einem einfachen Mikrofon erfolgen, etwa einem Smartphone oder über eine Aufnahme während eines Online-Meetings (z. B. über Zoom).
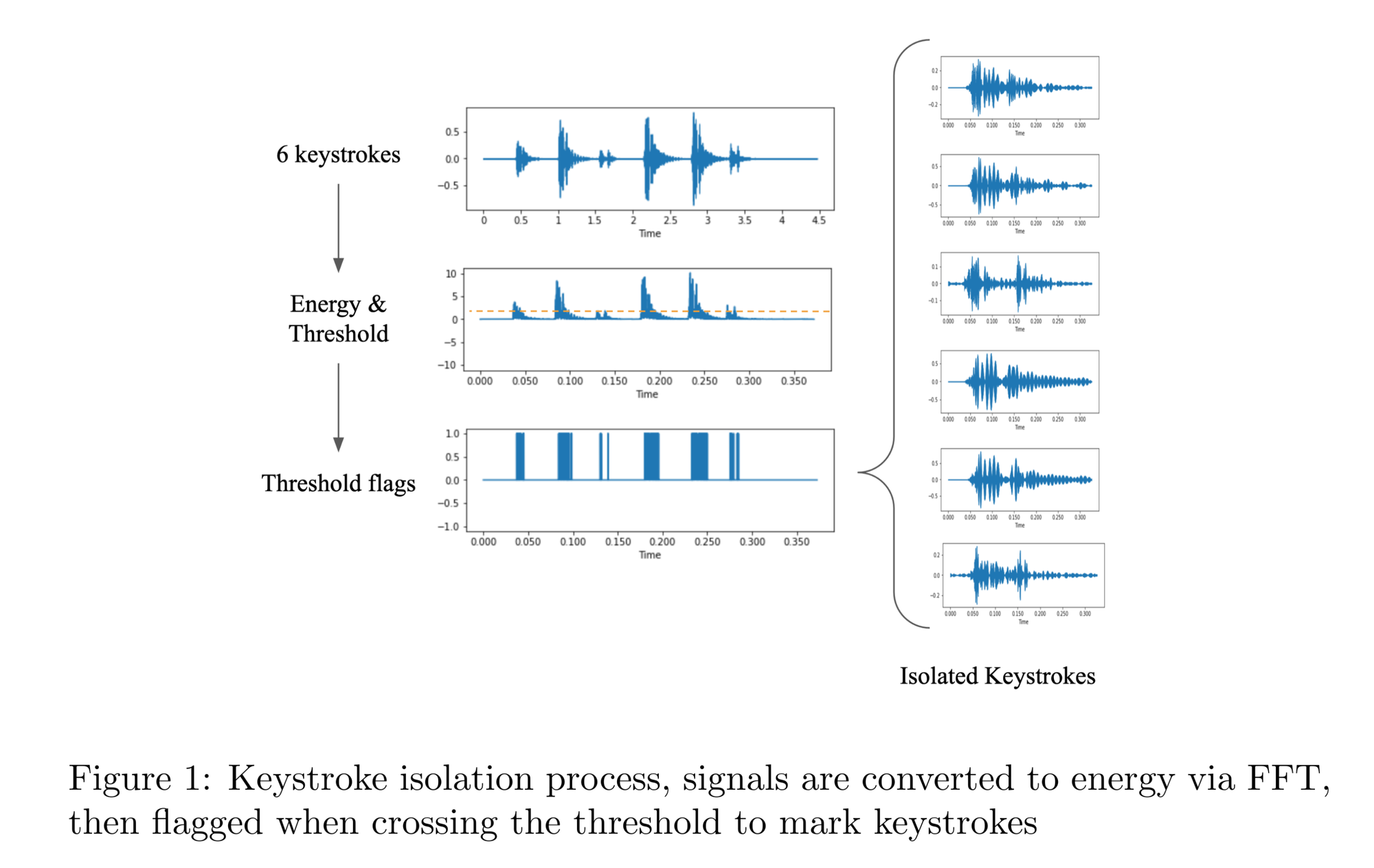
2. Keystroke-Isolierung
Sobald die Aufnahme gemacht wurde, muss der Angreifer die einzelnen Tastenanschläge aus dem Audio extrahieren. Dazu wird eine Fast Fourier-Transformation (FFT) verwendet, um die Energiespitzen im Signal zu erkennen, die durch das Drücken einer Taste entstehen. Die Tastenanschläge werden isoliert und in einzelnen Audio-Samples abgespeichert.
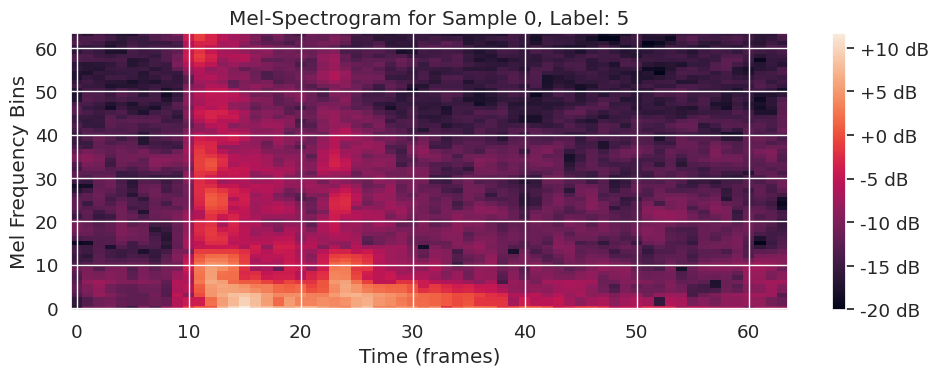
3. Feature-Extraktion
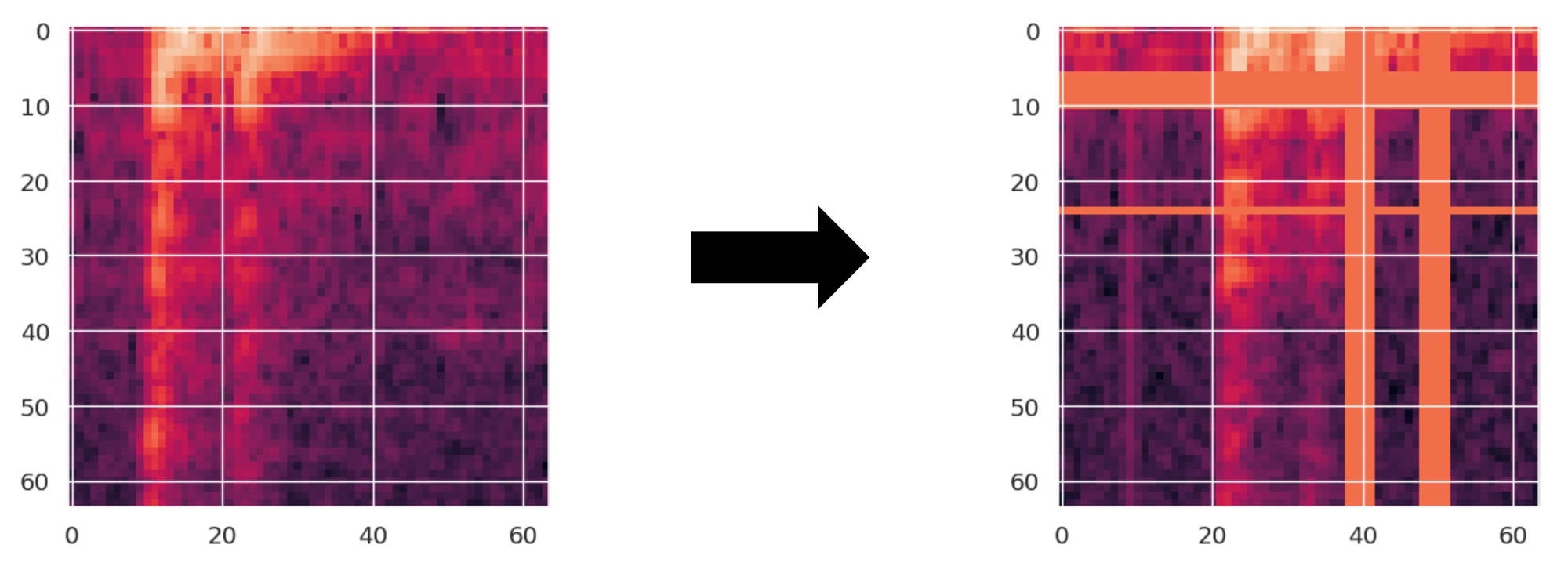
Im nächsten Schritt werden die isolierten Keystrokes in ein Format umgewandelt, das von einem Machine-Learning-Modell verstanden werden kann. Dafür verwenden wir sogenannte Mel-Spektrogramme, die die Frequenzverteilungen der Geräusche visuell darstellen. Um diese für das Training eines neuronalen Netzes weiter zu optimieren, setzen wir zusätzlich eine Technik der Data Augmentation namens SpecAugment ein, bei der ca. 10% des Bildes des Mel-Spektrogramms maskiert werden.
4. Modelltraining und Klassifikation
Das Herzstück des Angriffs ist ein Deep-Learning-Modell, das anhand der extrahierten Features die Tastenanschläge klassifiziert. Ein gängiges Modell, das in der Forschung eingesetzt wird, ist das sogenannte CoAtNet, das sowohl Convolutional Neural Networks (CNNs) als auch Transformer-Schichten kombiniert. Es eignet sich sehr gut um räumlichen Beziehungen zwischen Datenpunkten zu berücksichtigen, was besonders vorteilhaft für die Verarbeitung von 2D-Daten ist, wie es unsere Mel-Spektogramme sind. Das Modell wird darauf trainiert, die Unterschiede zwischen den Geräuschen der einzelnen Tasten zu erkennen und diese korrekt zuzuordnen.
Wie funktioniert CoAtNet?
CoAtNet integriert zwei grundlegende Technologien:
- Convolutional Layers (CNN) – CNNs sind bekannt für ihre Fähigkeit, lokale Muster in Daten zu erkennen. In unserem Fall bedeutet dies, dass die akustischen Eigenschaften von Tastenanschlägen wie Frequenzmuster und Energiespitzen lokal analysiert werden.
- Transformers – Transformers sind hervorragend geeignet, um globale Beziehungen in Daten zu lernen. Dies hilft bei der Analyse komplexer akustischer Muster, die über mehrere Tastenanschläge hinweg konsistent sind.

Architektur des CoAtNet
Die Architektur von CoAtNet besteht aus mehreren Schichten, die schrittweise Merkmale extrahieren:
- Stem Stage (S0):
Der Eingang (z. B. ein Mel-Spektrogramm) wird zuerst durch eine sogenannte "Stem Stage" geleitet. Diese besteht aus Faltungsschichten (Convolutions) und dient zur Reduzierung der räumlichen Dimensionen. - Mobile Inverted Bottleneck Convolution (MBConv):
Die ersten beiden Stufen (S1 und S2) nutzen MBConv-Blöcke. Diese Blöcke sind für die effiziente Extraktion lokaler Merkmale optimiert. Sie beinhalten Batch-Normalisierung, GELU-Aktivierungen und Squeeze-and-Excitation-Mechanismen, die die Wichtigkeit verschiedener Merkmale dynamisch anpassen. - Downsampling-Mechanismen:
Nach jeder Stufe wird die Eingabedimension durch Downsampling reduziert. Dies hilft, die Rechenkosten zu minimieren was zu einem schnelleren Modelltraining führt und gleichzeitig relevante Merkmale beizubehalten. - Transformer Layers (S3 und S4):
Die späteren Stufen nutzen Transformer-Blöcke mit 2D-Relativem Aufmerksamkeit-Mechanismus (RelativeAttention2d). Dieser Mechanismus ermöglicht es dem Modell, Beziehungen zwischen verschiedenen Positionen im Mel-Spektrogramm zu lernen - Feed-Forward Networks (FFN):
In jeder Stufe kommen Feed-Forward-Netzwerke zum Einsatz. Diese Netzwerke bestehen aus zwei linearen Schichten und helfen dabei, nichtlineare Transformationen der extrahierten Merkmale durchzuführen. Sie tragen wesentlich dazu bei, dass das Modell tiefere Repräsentationen der Eingabedaten lernt.
5. Rekonstruktion der eingegebenen Zeichen
Nachdem das Modell die Tastenanschläge klassifiziert hat, kann der Angreifer nun aus weiteren Audio-Samples die eingegebenen Zeichen rekonstruieren. Dies können Passwörter, Chatnachrichten oder andere vertrauliche Informationen sein.
Modelltraining und Daten
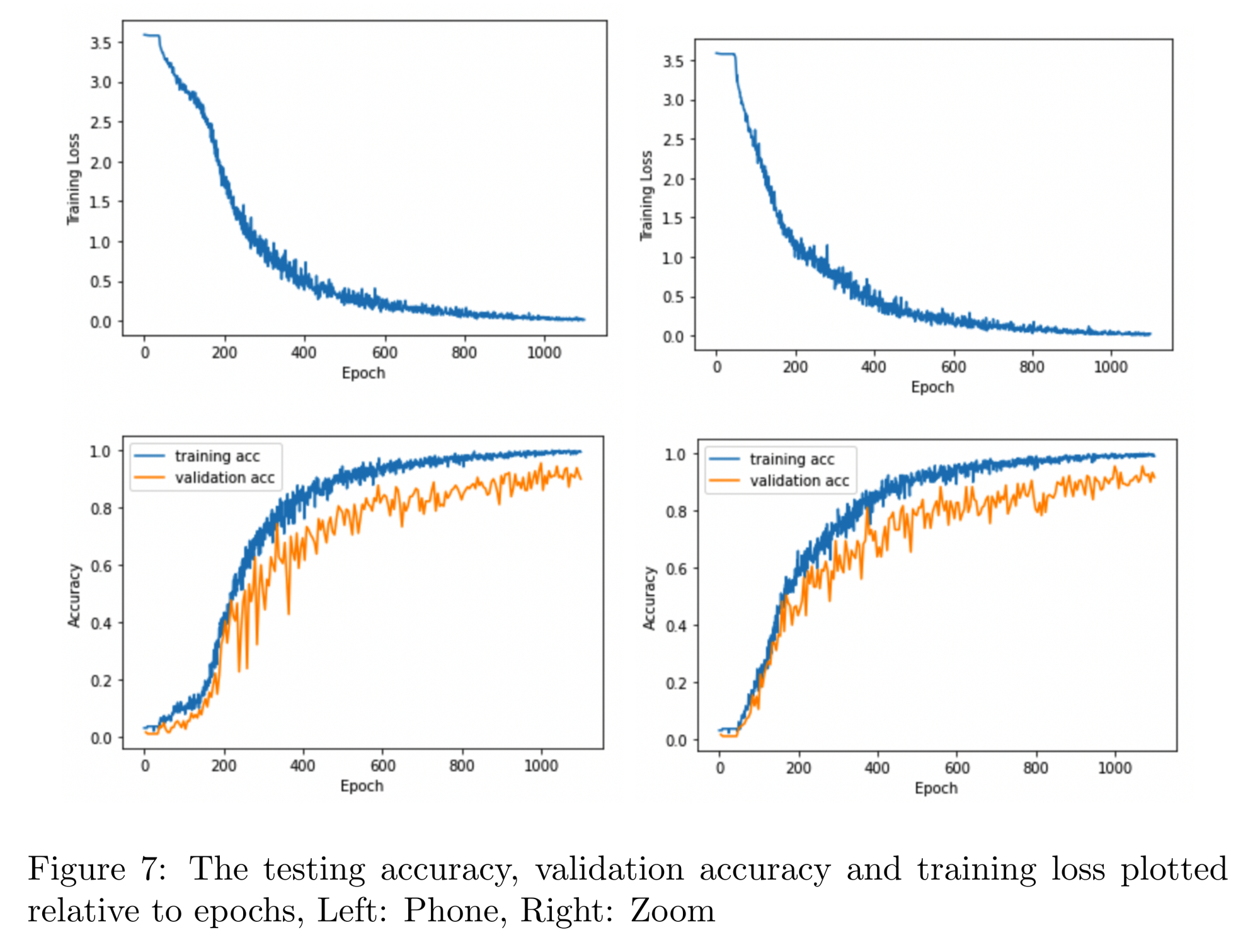
Das Modelltraining wurde mit Daten durchgeführt, die aus zwei verschiedenen Quellen stammen: einem vor Ort aufgenommenen Datensatz mit einem Smartphone-Mikrofon und einem zweiten Datensatz, der über Zoom aufgezeichnet wurde. Insgesamt wurden 36 verschiedene Tasten eines a MacBook Pro (a-z, 0-9) jeweils 25 Mal in unterschiedlichen Variationen gedrückt, um eine breite Palette von akustischen Mustern zu erfassen.
Hyperparameter-Einstellungen: Das Modelltraining erstreckte sich über 1100 Epochen, das heißt 1100 komplette Durchläufe durch den Datensatz mit einer anfänglichen Lernrate von 0,0005, die im Laufe des Trainings bis auf 0,000001 reduziert wurde. Als Optimierer wurde AdamW verwendet. Die Batchgröße betrug 16, und zur Vermeidung von Überanpassung wurden SpecAugment verwendet.
Ergebnisse:
Die Ergebnisse des Papers zeigen, dass akustische Seitenkanalangriffe mit erschreckend hoher Genauigkeit durchgeführt werden können. Durch ein in der Nähe der Tastatur platziertes Smartphone können Tastenanschläge mit einer Genauigkeit von 95 % erkannt werden. Selbst wenn die Geräusche über Videokonferenzsoftware wie Zoom aufgenommen werden, liegt die Erkennungsgenauigkeit noch bei 93 %.
Schutzmaßnahmen
Um sich vor akustischen Seitenkanalangriffen-Angriffen zu schützen, gibt es verschiedene Ansätze:
- Änderung des Tippstils: Die Forscher kamen zu dem Ergebnis, dass schon eine einfache Änderung des Tippstils z.B.: von einem Finger auf das 10-Fingersystem das Modell verwirren konnte.
- Verwendung von Zwei-Faktor-Authentifizierung (2FA): Selbst wenn ein Passwort abgefangen wird, schützt eine zusätzliche Authentifizierungsebene vor unbefugtem Zugriff.
- Erzeugung von Hintergrundgeräuschen: Das Abspielen von Rauschen oder Musik während der Eingabe kann die Effektivität von akustischen Angriffen verringern.
- Verwendung von biometrischen Authentifizierungsmethoden: Fingerabdruckscanner oder Gesichtserkennung können Passwörter ersetzen und das Risiko von Angriffen mindern.
Fazit
Akustische Seitenkanalangriffe sind eine ernstzunehmende Bedrohung, da sie nicht nur auf einzelne Individuen, sondern gegen ganze Personengruppen eingesetzt werden können. Mit einfachen Geräten und fortschrittlicher Software können Angreifer unbemerkt aus der Ferne sensible Informationen wie Passwörter oder vertrauliche Nachrichten abfangen, ohne physischen Zugang zu den Geräten ihrer Opfer zu benötigen.
Quellen
Besonders hervorzuheben ist das Paper "A Practical Deep Learning-Based Acoustic Side Channel Attack on Keyboards", das als erste den Einsatz von Deep Learning bei der Klassifizierung von Keystrokes angewendet hat.


